Introduction
Modern deep learning models are made up of hundreds or even thousands of operations. Each of these operations involves memory reads, computation, and memory writes, which when executed individually leads to substantial overhead. One of the most effective ways to cut down this overhead and boost performance is through graph fusion.
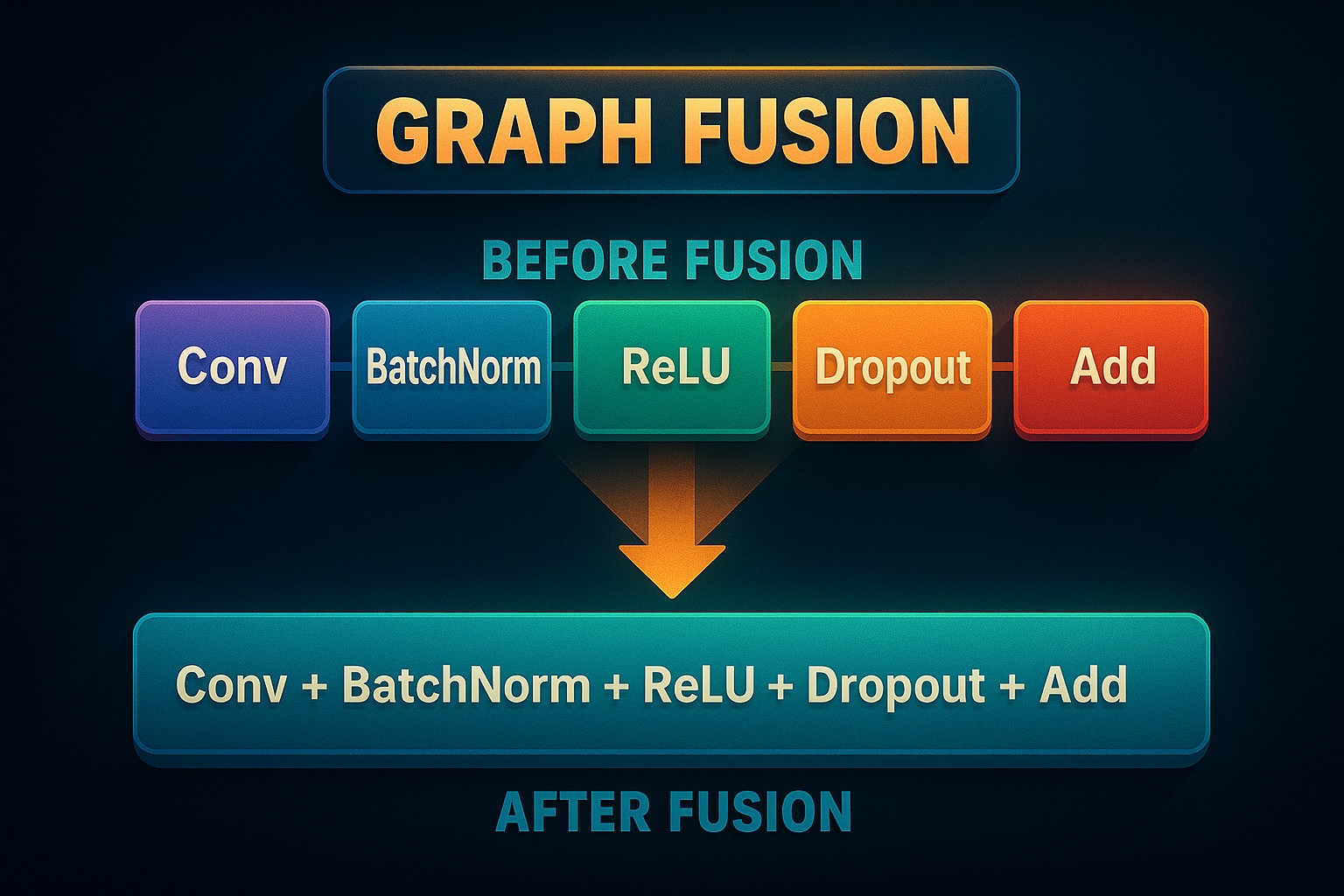
Graph fusion, also known as operation fusion or kernel fusion, refers to the process of merging multiple operations into a single, more efficient kernel. By combining adjacent operations like a convolution followed by batch normalization and a ReLU activation into one fused unit, deep learning frameworks can avoid unnecessary memory access, reduce kernel launch overhead, and take better advantage of hardware capabilities.
This optimization is applied under the hood by compilers and runtime engines like PyTorch’s TorchScript or ONNX Runtime’s graph transformers. For the end user, the result is faster model execution, with no changes needed to the model’s architecture.
In this post, we’ll explore how graph fusion works, what types of operations can be fused, and how different frameworks apply it. We’ll also walk through a concrete PyTorch example and examine when fusion offers the biggest benefits, and when it doesn’t.
What is Graph Fusion?
At its core, graph fusion is a compiler optimization technique that merges multiple adjacent operations in a computational graph into a single, more efficient operation. Instead of executing each operation independently, each with its own memory reads, computation, and memory writes, fusion allows these steps to be combined into one pass, reducing overhead and improving performance.
Think of it like combining multiple assembly lines into a single, streamlined process. For instance, a common sequence in neural networks, convolution → batch normalization → ReLU activation, can be fused into one operation that does all three steps at once. This avoids writing intermediate results to memory, launching multiple GPU kernels, or repeatedly switching contexts.
Graph fusion can occur at various levels of abstraction:
- High-level graph fusion, where entire layers or ops are merged during graph transformations (e.g., fusing a Conv + BatchNorm during model export or optimization).
- Low-level kernel fusion, where the fused operations are implemented as a single CUDA kernel.
- Dynamic fusion, where operations are fused at runtime based on input shapes and execution context.
The benefits of graph fusion are particularly important in deep learning workloads, where models are large, and even small inefficiencies can add up. Frameworks like PyTorch, TensorFlow, and ONNX Runtime all include backend compilers and execution engines that perform graph fusion under the hood to improve both training and inference performance.
Motivation for Fusion
To understand why graph fusion matters, we need to look at the inefficiencies in how deep learning models are typically executed.
Most neural networks are expressed as computational graphs where each node (operation) is executed independently: a convolution runs, writes its output to memory, batch normalization reads that output, processes it, and writes its own output, then ReLU does the same, and so on. Each step involves a memory read, computation, and memory write, plus a kernel launch on the GPU or CPU.
This process leads to several key performance bottlenecks:
1. Memory Bandwidth Bottlenecks
Modern accelerators like GPUs are extremely fast at computation, but they’re often limited by memory bandwidth. Writing intermediate results to memory and reading them back in the next op can consume more time than the computation itself. Fusing operations keeps intermediate values in registers or shared memory, drastically reducing memory traffic.
2. Kernel Launch Overhead
Each operation, especially on GPUs, requires launching a separate kernel. These launches aren’t free, they involve CPU-side scheduling, driver overhead, and context switches. By combining multiple operations into a single kernel, fusion minimizes launch overhead and improves throughput.
3. Better Cache and Register Utilization
Fusion keeps data closer to the compute units. Instead of flushing intermediate results to global memory (where latency is high), fused kernels can use registers or local memory, resulting in better locality and faster execution.
4. Reduced Latency and Improved Throughput
Ultimately, graph fusion speeds up inference and training. It’s especially important in latency-sensitive applications (e.g., real-time inference on edge devices), but also valuable at scale for reducing compute costs in the cloud.
Common Fusion Patterns
While in theory many operations can be fused, in practice, fusion works best when operations are adjacent, stateless, and element-wise or mathematically composable. Most frameworks and compilers include pattern-matching passes that look for common subgraphs that can be merged. Here are some of the most frequently fused patterns in modern deep learning:
Conv + BatchNorm (+ ReLU)
One of the most impactful fusion patterns. BatchNorm can be mathematically folded into Conv’s weights and bias, and ReLU can be appended as an activation. This reduces multiple operations into a single fused convolution kernel.
Let’s break this down and see how it can be fused into a single, optimized operation.
1. The Convolution Layer
A standard 2D convolution outputs:
$$ z = W * x + b $$
-
$W$: convolution weights
-
$b$: bias
-
$*$: convolution operation
-
$x$: input tensor
-
$z$: output feature map
2. The Batch Normalization Layer
BatchNorm, applied per channel, normalizes the output of the conv layer:
$$ \text{BN}(z) = \gamma \cdot \frac{z - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta $$
-
$\mu$, $\sigma^2$: running mean and variance (from training or inference stats)
-
$\gamma$, $\beta$: learned affine parameters
-
$\epsilon$: small constant for numerical stability
3. Combine Conv and BatchNorm
We substitute $z = W * x + b$ into the BN expression: $$ \text{BN}(W * x + b) = \gamma \cdot \frac{W * x + b - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta $$
Let’s define: $$ \alpha = \frac{\gamma}{\sqrt{\sigma^2 + \epsilon}}, \quad \beta’ = \beta - \alpha \cdot \mu $$
Then: $$ \text{BN}(W * x + b) = \alpha \cdot (W * x + b) + \beta - \alpha \cdot \mu = \alpha \cdot W * x + (\alpha \cdot b + \beta’) $$
So we can precompute: $$ W’ = \alpha \cdot W, \quad b’ = \alpha \cdot b + \beta' $$
Resulting in a single convolution with adjusted weights and biases: $$ y = W’ * x + b' $$
4. Add ReLU
ReLU is a pointwise operation: $$ y = \text{ReLU}(W’ * x + b’) $$
Because ReLU has no trainable parameters and is stateless, it can be appended directly to the fused operation, resulting in a fused Conv-BN-ReLU kernel.
5. Summary
By folding the BatchNorm parameters into the Conv weights and biases, and applying ReLU in-place, we eliminate:
-
The need to store the intermediate result after Conv.
-
One or two extra kernel launches.
-
Redundant memory bandwidth usage.
This fusion is both exact (no approximation) and cheap to compute, and is widely applied in inference for CNNs like ResNet, MobileNet, and EfficientNet.
MatMul + Bias + Activation
Fully connected layers often follow a matrix multiplication with a bias addition and an activation function like ReLU or GELU. These can be fused into a single GEMM (General Matrix Multiply) kernel.
Example pattern:
MatMul → Add (bias) → ReLU
↓
FusedLinearReLU
Chained Pointwise Ops
Operations like Add, Multiply, Sigmoid, Tanh, ReLU, etc., that operate element-wise on tensors can often be fused together into one kernel. This is especially helpful in transformers and MLP blocks where many such operations are chained.
Example pattern:
Add → Multiply → ReLU → Dropout
↓
FusedPointwiseKernel
Residual Blocks (Add + Activation)
In ResNet-style architectures, skip connections end with an element-wise Add followed by an activation. These two steps are often fused in inference for lower latency.
Example pattern:
Add → ReLU
↓
FusedAddReLU
Normalization + Activation
In transformer models, layer normalization followed by an activation like GELU is a candidate for fusion, especially in inference with fixed sequence lengths.
Note: Modern normalization layers like
LayerNormandRMSNorm, common in transformer-based architectures, cannot be fused with convolution layers, since they operate across different dimensions and rely on input-dependent statistics.
Fusion in Practice: Framework-Specific Techniques
While the concept of graph fusion is universal, its implementation varies across deep learning frameworks. Each framework has its own compiler stack, optimization passes, and APIs to expose or trigger fusion. Here’s how fusion is handled in the most widely used ecosystems:
PyTorch
PyTorch supports several forms of fusion, mostly applied at the graph level using TorchScript or FX:
-
torch.jit.trace/torch.jit.script: These convert Python-based models into a static computation graph. During tracing or scripting, PyTorch can detect common patterns and apply operator fusion automatically. -
fuse_modules(): Common in quantization pipelines, this utility can explicitly fuse submodules likeConv2d + BatchNorm2d + ReLU. It’s used during model preparation for quantized or optimized inference.
torch.quantization.fuse_modules(model, [["conv", "bn", "relu"]], inplace=True)
-
FX + TorchInductor: PyTorch 2.0 introduces a new compiler stack where models are transformed with FX (Functional Transformations) and lowered to optimized kernels using TorchInductor. This system performs aggressive fusion of pointwise ops, matrix multiplies, and even fuses with custom backends like Triton.
-
AOTAutograd + Triton: For training workloads, the AOTAutograd backend allows splitting the forward and backward graphs and fusing them across boundaries. Combined with Triton, it enables high-performance fused kernels.
TensorFlow
Fusion in TensorFlow is primarily handled by its optimization and compilation tools:
-
Grappler: TensorFlow’s default graph optimizer. It includes fusion passes for folding BatchNorm into Conv, combining pointwise ops, and eliminating redundant ops.
-
XLA (Accelerated Linear Algebra): A just-in-time compiler for TensorFlow graphs. When enabled (
@tf.function(jit_compile=True)), it lowers TensorFlow ops into a highly optimized fused kernel representation using HLO (High-Level Optimizer) IR.
@tf.function(jit_compile=True)
def fused_fn(x):
return tf.nn.relu(tf.nn.batch_normalization(tf.nn.conv2d(x, ...)))
- TF Lite & Edge TPU: TensorFlow Lite applies fusion passes when converting models for inference. It can fuse Conv+BN+Activation and quantize them into fused integer ops for efficient edge inference.
ONNX Runtime
ONNX Runtime performs fusion both during export and at runtime:
-
Graph Transformers: Optimization passes like
ConvBNFusion,GemmActivationFusion, andLayerNormFusionare run automatically when loading the graph, or via manual optimization scripts. -
Execution Providers (EPs): Fusion is often backend-dependent. For instance, the TensorRT EP or OpenVINO EP will apply hardware-specific fusion passes to accelerate execution.
-
Pretrained Model Optimizer Tools: ONNX Runtime provides CLI and Python tools (
optimizer.optimize_model) that allow you to export a fused version of your model for deployment.
Common Toolchains and Their Fusion Behavior
| Toolchain | Fusion Scope | Notes |
|---|---|---|
| TorchScript | Basic operator fusion | Works best with scripted models or traced subgraphs |
| TorchInductor | Advanced fusion (pointwise, matmul) | Can fuse forward & backward with AOTAutograd |
| ONNX Runtime | Predefined patterns (Conv+BN, etc.) | Requires export, supports EP-specific fusion |
| TensorRT | Aggressive layer fusion + quantization | Hardware-specific, works best with static shapes |
| XLA (TensorFlow) | High-level and low-level fusion | Fuses ops across control flow when possible |
Example: Fusing Conv + BatchNorm in PyTorch
To see graph fusion in action, let’s walk through a practical example of fusing a convolution and batch normalization layer in PyTorch. This pattern appears frequently in convolutional neural networks like ResNet and MobileNet, and fusing it can improve inference efficiency with no loss in accuracy.
Step 1: Define an Unfused Model
We’ll define a simple model with a convolution followed by batch normalization and ReLU:
import torch
import torch.nn as nn
class UnfusedConvBNReLU(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=True)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU()
def forward(self, x):
return self.relu(self.bn(self.conv(x)))
Step 2: Fuse the Layers
PyTorch provides a convenient method to fuse layers, especially useful when preparing a model for quantization or inference optimization:
model = UnfusedConvBNReLU().eval()
fused = torch.quantization.fuse_modules(model, [["conv", "bn", "relu"]], inplace=False).eval()
Step 3: Verify Correctness
You can check that the fused model behaves identically (within floating point tolerance):
input_tensor = torch.randn(1, 3, 224, 224)
with torch.no_grad():
output1 = model(input_tensor)
output2 = fused(input_tensor)
print(torch.allclose(output1, output2, atol=1e-5)) # Should print: True
Step 4: Benchmark the Difference
Let’s compare inference time using torch.cuda.Event for timing:
import time
model = model.cuda()
fused = fused.cuda()
input_tensor = input_tensor.cuda()
def benchmark(model, name):
model.eval()
with torch.no_grad():
# Warmup
for _ in range(100):
model(input_tensor)
# Timing
start = time.time()
for _ in range(1000):
model(input_tensor)
torch.cuda.synchronize()
end = time.time()
print(f"{name}: {(end - start)*1000:.2f} ms")
benchmark(model, "Unfused")
benchmark(fused, "Fused")
Output (run on google colab’s T4):
Unfused: 564.98 ms
Fused: 226.02 ms
You’ll often see small but meaningful improvements in runtime, especially for models with many such blocks.
What Actually Happened?
The fused model doesn’t introduce new behavior, it just rewrites the operations into a more efficient execution pattern. During export or ahead-of-time compilation (e.g., TorchScript + TorchInductor), the compiler can now emit a single kernel for the entire fused block, saving memory and execution time.
When Graph Fusion Helps (and When It Doesn’t)
Graph fusion can dramatically improve the performance of deep learning models, but its effectiveness depends on the structure of your model, the execution environment, and the framework/compiler being used. Here’s when it delivers the most benefit, and when its impact may be limited.
When Graph Fusion Helps
1. Inference on Edge Devices or CPUs
Devices like phones, microcontrollers, and Raspberry Pi have limited memory bandwidth and compute power. Fusion reduces kernel launches and memory access, which is crucial on such constrained hardware.
2. Large Models with Repeated Blocks
Models like ResNet, MobileNet, or ViT use many repeatable blocks (Conv → BN → ReLU). Fusion applies uniformly across these patterns, compounding the performance benefit.
3. Pointwise Operation Chains
Transformers and MLPs often contain sequences of element-wise ops. Fusing them into a single kernel reduces overhead and avoids materializing unnecessary intermediate tensors.
4. Exported or Compiled Models
If you export your model using TorchScript, ONNX, or TensorFlow Lite, fusion is often applied as part of the optimization pass, making deployment faster without any model changes.
5. Latency-Critical Applications
In real-time systems (e.g., robotics, AR, recommendation engines), shaving off even milliseconds of latency matters. Fusion can provide quick wins without redesigning the model.
When Fusion Doesn’t Help (Much)
1. Dynamic Control Flow
If your model includes if/while statements or data-dependent logic, fusion may not be applied. Compilers often require static graphs to match fusion patterns reliably.
2. Already-Bound Memory Bottlenecks
If your model’s performance is limited by I/O, disk access, or network latency (e.g., in large-scale distributed inference), fusion might not make a noticeable dent.
3. Small Models with Few Ops
For tiny models (e.g., simple MLPs with 2–3 layers), the overhead that fusion eliminates is already minimal. Gains may be negligible.
4. Training with Frequent Weight Updates
In training mode, batch norm uses live batch statistics, and some fused operations (especially with quantization) may not be numerically identical. Fusion is usually more aggressive in inference.
5. Ops with Side Effects
Certain operations like Dropout or custom loss functions can’t always be fused, especially if they have randomness or state.
6. Limited Fusion in Attention Blocks
In attention-based models, full fusion is limited due to operations like softmax and masking. However, earlier stages such as projection layers followed by activation functions are typically fusible, especially if implemented in a standard way.
Conclusion
Graph fusion is one of the most impactful, low-effort ways to optimize deep learning models. By merging multiple adjacent operations into a single fused kernel, it reduces memory access, kernel launch overhead, and runtime latency, often with zero changes to model accuracy or behavior.
While fusion happens mostly under the hood, understanding how it works, and when it applies, can help you build more efficient models and make smarter deployment decisions. Whether you’re exporting a model for inference, compiling for edge devices, or optimizing training with PyTorch’s AOTAutograd, fusion plays a central role in turning your model into a high-performance executable.
As frameworks and compilers evolve, fusion is becoming more dynamic, hardware-aware, and integrated with other optimization techniques like quantization, pruning, and code generation. It’s no longer just a backend trick, it’s a key part of how modern deep learning systems scale.